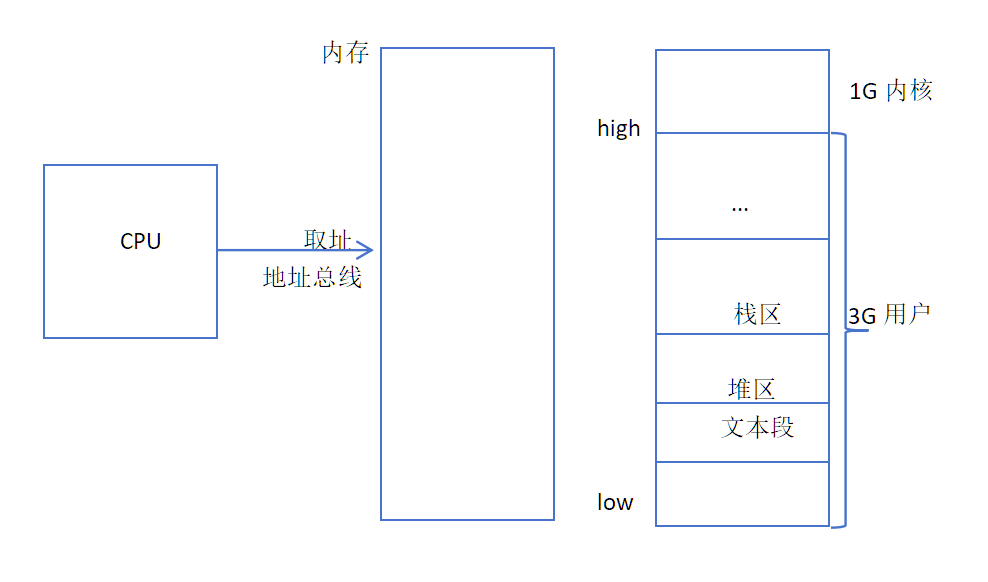
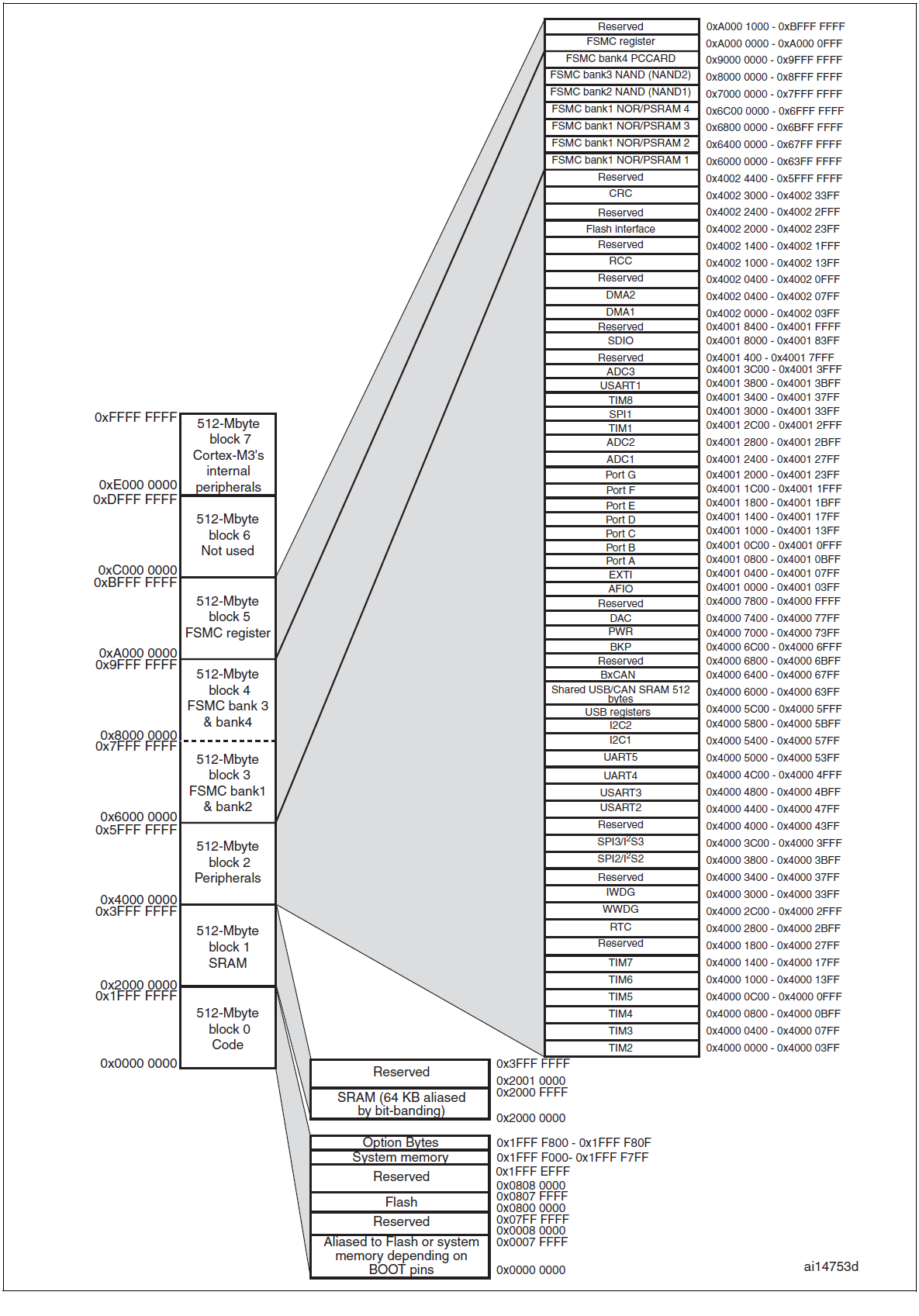
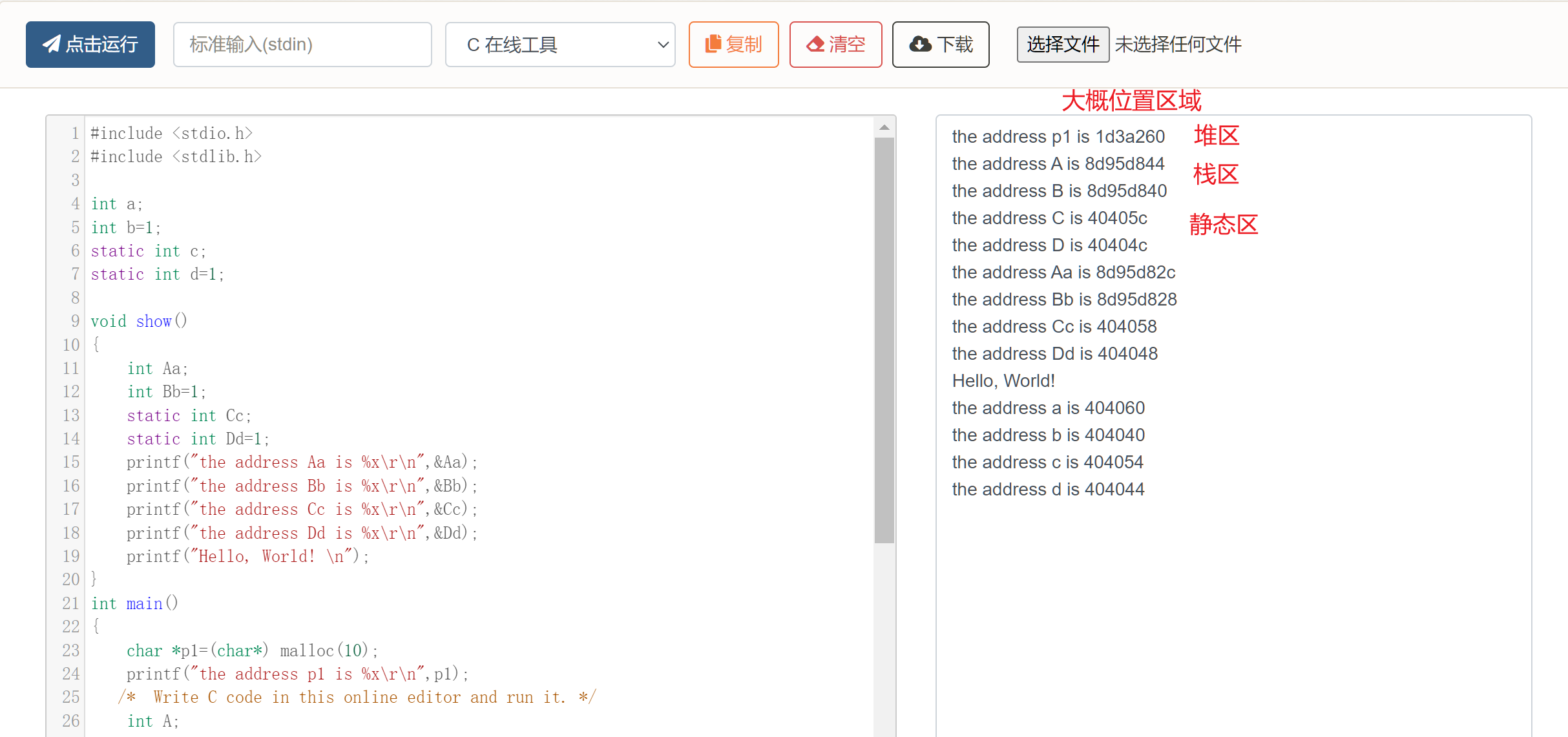
内存空间:
测试数据分布情况代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <stdio.h> #include <stdlib.h> int a;int b=1 ;static int c;static int d=1 ;void show () { int Aa; int Bb=1 ; static int Cc; static int Dd=1 ; printf ("the address Aa is %x\r\n" ,&Aa); printf ("the address Bb is %x\r\n" ,&Bb); printf ("the address Cc is %x\r\n" ,&Cc); printf ("the address Dd is %x\r\n" ,&Dd); printf ("Hello, World! \n" ); } int main () { char *p1=(char *) malloc (10 ); printf ("the address p1 is %x\r\n" ,p1); int A; int B=1 ; static int C; static int D=1 ; printf ("the address A is %x\r\n" ,&A); printf ("the address B is %x\r\n" ,&B); printf ("the address C is %x\r\n" ,&C); printf ("the address D is %x\r\n" ,&D); show(); printf ("the address a is %x\r\n" ,&a); printf ("the address b is %x\r\n" ,&b); printf ("the address c is %x\r\n" ,&c); printf ("the address d is %x\r\n" ,&d); return 0 ; }
编程知识 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 C语言中的常用关键字包括以下内容: auto break case char const continue default do double else enum extern float for goto if int long register return short signed sizeof static struct switch typedef unsigned void volatile while
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 在C语言中,static 是一个关键字,它有几个不同的用途。以下是static 的一些常见用法: 1. 局部变量:在函数内部,如果一个变量被声明为static ,那么它的生命周期将延长到程序的整个运行时间,而不仅仅是该函数的执行时间。此外,它的值在函数调用之间保持不变。void func () { static int count = 0 ; count++; printf ("%d\n" , count); } 每次调用func()时,count的值都会增加,而不是重置为0 。 2. 全局变量和函数:当一个变量或函数在文件的全局范围内被声明为static 时,它的作用范围被限制在该文件内。其他文件无法访问这个变量或函数。这可以用来创建只能在特定文件中使用的变量或函数。3. 静态数组和结构:当声明一个数组或结构为static 时,它意味着该数组或结构的大小在编译时确定,并且不能更改。4. 静态指针:可以声明一个指针为static ,这意味着该指针在程序的生命周期内始终存在,而不是在每次函数调用时重新分配。5. 静态类成员:在C++中,static 关键字用于类中,表示该成员与类本身关联,而不是与类的特定对象关联。使用static 关键字时,应明确其用途,因为不同的使用方式可能导致预期之外的行为。
1 2 3 4 5 6 在C语言中,const 和static 是两个不同的关键字,它们各自具有不同的用途和含义。 关于const int *p和int * const p这两种声明方式,它们也具有不同的含义。 const int *p:这里,const 关键字修饰的是指针p所指向的整型变量,表示该整型变量是不可修改的。因此,这个声明表示一个指向常量整型的指针,即指针p可以指向一个整型变量,但这个整型变量不能被修改。int * const p:这里,const 关键字修饰的是指针p本身,表示指针p是一个常量指针,即它指向的地址是固定的,不能被修改。因此,这个声明表示一个指向整型的常量指针,即指针p所指向的整型变量可以被修改,但指针p本身不能被重新赋值指向其他地址。综上所述,const int *p和int * const p的区别在于:前者是指针指向一个不可修改的整型变量,后者是指针本身是常量指针,但其指向的整型变量可以修改。
sizeof和strlen是C语言中用于处理数据和字符串的两个重要函数,但它们的功能和使用方式有所不同。
sizeof:这是一个运算符,用于获取数据类型或变量在内存中所占的字节数。它可以用于数组、结构体、指针等。 例如,sizeof(int)将返回一个整型变量在内存中所占的字节数,sizeof(array)将返回整个数组在内存中所占的字节数。
1 2 3 例子: int a; printf ("%lu" , sizeof (a));
strlen:这是一个函数,用于计算字符串的长度,但不计算终止字符’\0’。它返回的是字符串中的字符数,不包括终止的’\0’。
1 2 3 例子: char str[] = "Hello" ; printf ("%lu" , strlen (str));
注意:sizeof返回的是字节数,而strlen返回的是字符数。在ASCII码中,一个字符通常占用一个字节,但在某些编码中(如UTF-8),一个字符可能需要多个字节。因此,这两个函数在处理字符串和数据时具有不同的用途。
指针: 1 2 3 4 5 6 char * p;int * p;怎么储存 32 位,4 字节怎么读取 按类型读取
数组: 1 2 3 4 5 数组名:常量标签 数组是通过一个标识符(数组名)和索引来访问数组中的元素.C语言中的数组索引是从0 开始的,因此数组中的元素可以通过索引0 到n-1 来访问,其中n是数组的大小。 int arr[] = {1 , 2 , 3 , 4 , 5 };char str[][10 ] = {"Hello" , "World" , "C" };char str[10 ] = "Hello" ;
结构体: 1 2 3 4 5 typedef struct node { int data; struct node *next ; }Lnode,*LNODE;
1 2 3 4 5 6 7 8 9 10 11 12 typedef struct node { int data; struct node *next ; } Node, *NodePtr; Node myNode; NodePtr myPointer;
环形缓冲区: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct rt_ringbuffer { rt_uint8_t *buffer_ptr; rt_uint16_t read_mirror ; rt_uint16_t read_index ; rt_uint16_t write_mirror ; rt_uint16_t write_index ; rt_int16_t buffer_size; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <stdio.h> #include <stdlib.h> #define BUFFER_SIZE 10 typedef struct { int buffer[BUFFER_SIZE]; int head; int tail; } CircularBuffer; void init_buffer (CircularBuffer *cb) { cb->head = 0 ; cb->tail = 0 ; } int is_empty (CircularBuffer *cb) { return cb->head == cb->tail; } int is_full (CircularBuffer *cb) { return (cb->head + 1 ) % BUFFER_SIZE == cb->tail; } void write_data (CircularBuffer *cb, int data) { if (is_full(cb)) { printf ("Buffer is full, cannot write.\n" ); return ; } cb->buffer[cb->head] = data; cb->head = (cb->head + 1 ) % BUFFER_SIZE; } int read_data (CircularBuffer *cb) { if (is_empty(cb)) { printf ("Buffer is empty, cannot read.\n" ); return -1 ; } int data = cb->buffer[cb->tail]; cb->tail = (cb->tail + 1 ) % BUFFER_SIZE; return data; } int main () { CircularBuffer cb; init_buffer(&cb); write_data(&cb, 1 ); write_data(&cb, 2 ); write_data(&cb, 3 ); printf ("%d\n" , read_data(&cb)); printf ("%d\n" , read_data(&cb)); printf ("%d\n" , read_data(&cb)); printf ("%d\n" , read_data(&cb)); return 0 ; }
链表: 1 2 3 4 5 6 7 链表(Linked List)是一种常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。链表的节点可以动态地添加和删除,因此链表具有动态内存分配的特性。 链表可以分为单向链表、双向链表和循环链表等类型。单向链表的节点只有一个指针指向下一个节点,而双向链表的节点有两个指针,一个指向前一个节点,另一个指向后一个节点。循环链表的最后一个节点指向第一个节点,形成一个环形结构。 链表的主要操作包括插入、删除、查找等。插入操作是指在链表的头部或尾部添加一个新的节点,而删除操作则是删除链表中的一个节点。查找操作则是根据节点的数据元素在链表中查找对应的节点。 链表在计算机科学中有着广泛的应用,特别是在内存管理中。由于链表的节点可以动态地添加和删除,因此链表可以用于实现动态内存分配和垃圾回收等功能。此外,链表还可以用于实现其他数据结构,如栈、队列等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 以下是一个简单的C语言链表实现示例: #include <stdio.h> #include <stdlib.h> struct Node { int data; struct Node * next ; }; struct Node* createNode (int data) { struct Node * newNode =struct Node*)malloc (sizeof (struct Node)); newNode->data = data; newNode->next = NULL ; return newNode; } void insertAtHead (struct Node** head, int data) { struct Node * newNode = newNode->next = *head; *head = newNode; } void insertAtTail (struct Node** head, int data) { struct Node * newNode = if (*head == NULL ) { *head = newNode; return ; } struct Node * current = while (current->next != NULL ) { current = current->next; } current->next = newNode; } void deleteNode (struct Node** head, int data) { struct Node * current = struct Node * previous =NULL ; while (current != NULL && current->data != data) { previous = current; current = current->next; } if (current == NULL ) { printf ("Value not found in the list.\n" ); return ; } if (previous == NULL ) { *head = current->next; } else { previous->next = current->next; } free (current); } void printList (struct Node* head) { while (head != NULL ) { printf ("%d " , head->data); head = head->next; } printf ("\n" ); } int main () { struct Node * head =NULL ; insertAtHead(&head, 1 ); insertAtTail(&head, 2 ); insertAtTail(&head, 3 ); printList(head); deleteNode(&head, 2 ); printList(head); return 0 ; }
namespace {} namespace是一个用来防止命名冲突的特性。允许你将相关的变量、函数、类等封装在一个单独的命名空间中,这样就可以避免与其他代码的命名冲突。
在C++中,你可以使用namespace关键字来创建一个命名空间。例如:
1 2 3 4 5 6 namespace MyNamespace { int x = 10 ; void print () std::cout << "Hello from MyNamespace!" << std::endl; } }
在这个例子中,我们创建了一个名为MyNamespace的命名空间,并在其中定义了一个整数变量x和一个函数print()。你可以使用这个命名空间来调用它的成员,如下所示:
1 2 MyNamespace::print (); std::cout << MyNamespace::x << std::endl;
::与: 在C++中,:: 和 : 都是作用域解析运算符,但它们的使用场景和目的有所不同。
:::
:: 用于指定全局作用域。还可以用于指定类或命名空间的成员。例如,A::x 表示类A的成员x。
在模板编程中,:: 用于指定模板的特化或实例化。
:(单冒号):
: 用于初始化列表中,用于指定成员的初始化顺序。例如,A::B b1 : 10; 表示b1使用10个单位的大小进行初始化。定义类的继承
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> class C { public : void sayHello () std::cout << "Hello from C!" << std::endl; } }; class A { public : class B : public C { public : void printInfo () std::cout << "Info from B in A." << std::endl; } }; }; int main () A a; A::B b; b.printInfo (); b.sayHello (); return 0 ; }
A::B():C {}
A::B() : C {} 是一个构造函数和初始化列表的组合。
Frame::Frame(const Frame &frame) :mpORBvocabulary(frame.mpORBvocabulary){}复制构造函数是一种特殊的构造函数,它用于初始化一个对象,作为现有对象的副本。这个复制构造函数Frame::Frame(const Frame &frame)接收一个const Frame &frame参数,这是要复制的对象。在初始化列表中,它复制了frame.mpORBvocabulary成员到新创建的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class C { public : C () { } }; class A { public : C c; class B { public : B () : c (c) { } }; };
在这个例子中,A::B() 是一个构造函数,它属于 A 类的内部类 B。这个构造函数有一个初始化列表 : c(c),它用于初始化 B 类中的成员 c。这里,c(c) 表示将 B 类中的 c 初始化为 A 类中的 c 的值。
初始化列表在构造函数执行之前运行,用于初始化类的成员变量。在这个例子中,c(c) 确保 B 类中的 c 在 B 的构造函数体执行之前被正确初始化。
cv::Mat cv::Mat是OpenCV库中用于表示图像或矩阵的主要数据结构。它是一个多维密集数组,可以存储任意维度的稠密数据。在图像处理中,cv::Mat通常用于存储和处理图像数据。Mat是OpenCV中的一个类 ,用于存储矩阵数据的类型。Mat类十分庞大,其所涉及的成员函数和变量难以一一细数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <opencv2/opencv.hpp> #include <opencv2/highgui/highgui.hpp> int main () cv::Mat image = cv::imread ("image.jpg" ); if (image.empty ()) { std::cout << "无法加载图像" << std::endl; return -1 ; } cv::namedWindow ("Image" , cv::WINDOW_AUTOSIZE); cv::imshow ("Image" , image); cv::waitKey (0 ); return 0 ; }
在这个示例中,我们使用cv::imread函数读取一个图像文件,并将其存储在cv::Mat对象中。然后,我们使用cv::namedWindow和cv::imshow函数显示图像。最后,我们使用cv::waitKey函数等待用户按下任意键退出窗口。